SL1680 AI快速开发手册
一、概述
为帮助零基础用户快速完成在深蕾SL1680开发板上的项目开发,本文提供了一份基本开发教程, 包括搭建开发环境、模型转换、模型量化、板端实测等步骤,并结合YOLOV8模型实例进行讲解。 旨在用户快速熟悉SL1680的使用方法,方便后续项目开发。
二、硬件开发板
SL1680 BPI开发板如下图所示:

BPI开发板实物图
更多硬件参数可参考链接: SL1680用户指南
三、软件开发环境
3.1 搭建模型转换开发环境
深蕾astra系列芯片(SL1680/SL1640)仅支持专有格式的模型文件( .synap 、 .nb ),
因此用户需要通过深蕾平台提供的模型转换工具(synap软件包)将自有模型文件转换为专有模型文件。
针对转换工具的环境搭建,本文提供了基于conda环境和基于docker镜像两种方式,
用户可选择其中任意一种即可。
转换工具软件包可在下面的github地址中查看:https://github.com/synaptics-synap/toolkit/releases/tag/v3.1.0
本地PC开发环境要求:
1、ubuntu系统>= 22.04(若系统低于22.04,只能选择docker安装转换工具包)
2、python >= 3.10
3、docker或者conda
3.1.1 基于conda构建开发环境
1、安装anaconda软件
若用户已安装,可直接忽略此步骤。
本文以ubuntu 22.04下安装2023.07版本为例,用户也可自行选择其他conda版本:
#在清华镜像源中下载软件包,选择Anaconda3-2023.07-2-Linux-x86_64.sh
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
#更改安装包权限
chmod +x Anaconda3-2023.07-2-Linux-x86_64.sh
#启动安装
./Anaconda3-2023.07-2-Linux-x86_64.sh
安装过程中会弹出一些设置问题,直接敲 enter 键,使用默认值一路往下安装即可。
2、创建conda虚拟环境
#创建一个名为SL1680的conda环境,并在创建时自动安装python 3.10版本;
conda create --name SL1680 python=3.10
安装完成后,输入 conda env list 验证是否安装成功;如输出类似如下,则表示安装成功。
# conda environments:
#
base /your/ptah/anaconda3
SL1680 /your/ptah/anaconda3/envs/SL1680
3、使用pip安装模型转换工具synap以及相关依赖包
#激活安装的虚拟环境
conda activate SL1680
#使用pip安装软件包
pip install "https://github.com/synaptics-synap/toolkit/releases/download/v3.1.0/synap-20240625200405-cp310-cp310-linux_x86_64.whl" --extra-index-url https://download.pytorch.org/whl/cpu
用户ubuntu系统版本需是22.04及以上,python版本建议3.10,否则在模型转换时会出现转换失败的情况。
4、验证是否安装成功
输入 pip show synap 查看是否安装成功,若输出类似如下表示安装成功:
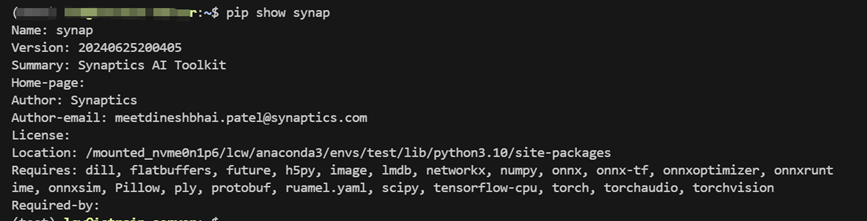
验证是否安装成功
3.1.1 基于docker镜像构建开发环境
1. 安装docker软件
若用户电脑系统已经安装好了docker,可直接忽略此步骤,同样以ubuntu 22.04系统为例:
apt-get install docker.io
要想在没有超级用户的情况下运行docker,还需要在安装完docker后运行下面的几条命令,
更多信息请参阅: https://docs.docker.com/engine/install/linux-postinstall/。
# 创建 docker 组(如果还不存在)
sudo groupadd docker
# 将当前用户添加到 docker 组
sudo usermod -aG docker $USER
#重启 Docker 服务
sudo systemctl restart docker
#重新登录
su - $USER
#验证当前用户是否已经成功添加到 docker 组
Groups
#如果成功,输出如下形式信息:yourusername : yourusername adm cdrom sudo docker
2. 下载带有synap的镜像文件
#下载3.1.0版本的模型转换工具镜像文件:
docker pull ghcr.io/synaptics-synap/toolkit:3.1.0
#下完完成后,可以通过docker images查看镜像信息
Docker images
#输出信息如下:
REPOSITORY TAG IMAGE ID CREATED SIZE
ghcr.io/synaptics-synap/toolkit 3.1.0 e87f51b29e18 7 weeks ago 4.26GB
该镜像不仅包含转换工具本身,还包含所有必需的依赖项和额外的案例程序。
您可以在以下网址中找到工具包的最新镜像: https://github.com/synaptics-synap/toolkit/pkgs/container/toolkit。
3、创建容器
在运行容器时,可以通过加载相应的目录来访问主机文件系统中的源模型和转换后的模型文件。
为避免在每次执行时手动指定这些选项,
建议创建一个简单的别名并将其添加到用户的启动文件中(如 .bashrc 或 .zshrc ):
alias synap='docker run -i --rm -u $(id -u):$(id -g) -v $HOME:$HOME -w $(pwd) ghcr.io/synaptics-synap/toolkit:#SyNAP_Version#'
这些选项的含义如下:
-i:以交互的方式式运行容器(从 stdin 读取数据的命令需要,如 image_od)。
--rm:退出时删除容器(不再需要已停止的容器)
-u $(id -u):$(id -g):以当前用户身份运行容器(因此文件要具有正确的访问权限)
-v $HOME:$HOME:挂载用户的主目录,使其全部内容在容器内可见。如果某些模型或数据位于主目录之外, 可以通过复用 -v 选项挂载其他目录,例如添加:
-v /mnt/data:/mnt/data。 注意:要在容器内外指定相同的路径,这样绝对路径才能正常工作。-w $(pwd):将容器的工作目录设置为当前目录,以便正确解析命令行中指定的相对路径。
在终端输入 synap help 查看容器信息
#查看synap相关信息
$ synap help
SyNAP Toolkit
Docker alias:
alias synap='docker run -i --rm -u $(id -u):$(id -g) -v : -w $(pwd) ghcr.io/synaptics-synap/toolkit:3.1.0'
Use multiple -v options if needed to mount additional directories, e.g.: -v /mnt/data:/mnt/data
Usage:
synap COMMAND ARGS
Run 'synap COMMAND --help' for more information on a command.
Commands:
convert Convert and compile model
help Show help
image_from_raw Convert image file to raw format
image_to_raw Generate image file from raw format
image_od Superimpose object-detection boxes to an image
version Show version
3.2 模型转换和量化
- 目前synap转换工具支持以下通用模型文件的格式转换:
tflite
onnx
torchscript
tflite 和 tocrchscript 分别是使用tensorflow和pytorch训练后得到的AI模型文件。
而onnx是一种灵活的文件格式,它独立于各种深度学习框架,支持将不同训练框架得到的模型文件转为onnx文件,
从而使模型能够在不同的框架之间无缝转换和部署。建议用户先将自有的模型文件转为onnx文件,
之后再利用synap转换工具将onnx文件转为 *.synap 文件并最终烧入开发板运行。
接下来我们以yolov8模型为例,完整为用户讲解模型的转换、量化以及最终的板端推理验证。
3.2.1 准备yolov8模型文件
Yolov8是由Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本, 它在原先YOLO系列基础上进行了改进,进一步提升了算法性能和灵活性。
具体细节可访问yolov8官网: https://docs.ultralytics.com/zh。
1、安装官方提供的yolov8工具包
#在conda环境中使用pip安装
pip install ultralytics
Yolov8提供了针对目标检测、图像分类、图像分割、人体姿态检测、定向目标检测等不同任务的算法模型。 这里,我们以常用的目标检测模型为例进行讲解,若您有其他方面的任务需求,如图像分割、人体姿态检测, 可通过官网选取相应的模型文件下载。
2、下载目标检测模型文件并保存为onnx文件
yolo export model=yolov8n.pt format=onnx imgsz=640
Yolov8提供了n、s、m、l、x共5种大小的预训练模型,这里我们选用最小的n级模型,
format=onnx : 表示输出的模型文件为onnx格式;
imgsz=640 : 这里我们设置模型的输入大小是640×640,用户也可以指定其他大小的输入。
3.2.2 模型转换
如果只是将下载的yolov8 onnx模型文件转为深蕾平台专用synap文件而不对模型进行量化处理,则直接运行转换命令即可,
#Docker下转换命令:
synap convert --model yolov8n.onnx --target SL1680 --out-format nb --out-dir converted
#conda下转换命令:
synap_convert --model yolov8n.onnx --target SL1680 --out-format nb --out-dir converted
这里涉及到三个输入:
--model:待转换的模型文件
--target:目标平台,即我们将要部署模型的芯片型号
--out-format:设置模型输出文件格式为*nb格式,synap工具3.0版本以上支持输出*nb和*synap两种格式的模型文件。
--out-dir:转换后的模型保存路径,这里我们设置将模型保存在同级路径下的converted文件夹下。
转换完成后,在converted文件下会得到如下几个文件:cache 、model.nb 、model.json 、model_info.txt ;
其中``model.nb`` 、model.json 是转换后的模型文件,其余2个文件是转换时附带生成的信息记录文件。
此时,我们仅是对模型完成了文件格式转换,并没有对模型进行量化处理,因此转换得到的模型是float16位的半精度模型, 虽然也可以直接烧入开发板中运行,但通常我们希望能够更高效的在开发板上执行模型推理, 因此建议尽可能对模型进行量化处理。
3.2.3模型量化
相比于上述的模型转换,我们仅需提供一个yaml文件即可完成对模型的量化和格式转换,新的命令如下:
#Docker下转换命令:
synap convert --model yolov8n.onnx --meta synap.yaml --target SL1680 --out-format nb --out-dir converted
#conda下转换命令:
synap_convert --model yolov8n.onnx --meta synap.yaml --target SL1680 --out-format nb --out-dir converted
synap.yaml 是写入了量化选项的设置文件。其中主要包含了对模型输入和输出的设置、
模型参数的量化类型、输入预处理等设置。这里提供的yaml文件内容如下:
inputs:
- name: images
shape: [1, 3, 640, 640]
scale: 255
format: rgb
outputs:
- name: output0
dequantize: true
format: yolov8 w_scale=640 h_scale=640
quantization:
data_type:
'*': uint8
dataset:
- ./*.jpg
inputs 、 outputs 分别代表模型的输入和输出设置、
quantization 表示量化时的设置,接下来我们将详细讲解这些参数设定。
首先我们可以通过网页 https://netron.app 加载原始的onnx模型文件。该网页是一个第三方网络结构可视化工具。 通过它,我们可以很清楚的看到模型的每一个节点。
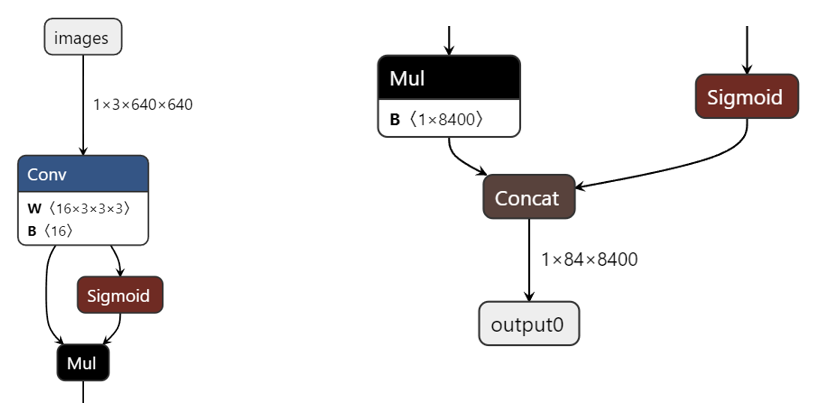
onnx模型节点
借助 https://netron.app 我们可以看到模型的输入节点是images,其输入大小是:1×3×640×640 。 模型的输出节点是output0;接下来我们在量化文件yaml中对输入进行设置:
inputs:
- name: images # 模型输入节点的名称
shape: [1, 3, 640, 640] # 输入的数据格式
scale: 255 # 对输入进行标准化处理,这里对输入的每一个像素值除以255
format: rgb # 输入的是rgb图像
对输出节点的设置:
outputs:
- name: output0
dequantize: true
format: yolov8 w_scale=640 h_scale=640
output0 为模型的输出节点名称,
dequantize: true :表示对模型的输出进行反量化处理,
因为原始模型的输出是float类型,但是量化后的模型其输出一般是int8、uint8、int16类型,
所以需要对输出结果进行反量化处理,以保证输出类型一致。
format: yolov8 w_scale=640 h_scale=640:这里调用深蕾封装的api接口完成网络输出的后处理工作。
深蕾平台针对一些常见的网络模型如:yolov5、yolov8、retiannet、mobilenet等网络提供了后处理api接口,
当用户使用这些模型时,可直接调用相应的api接口完成后处理工作,无需再自己手动去编写这些后处理代码,
从而提升用户的开发效率。这里调用yolov8的后处理api接口,同时指定模型输入的h和w是640,
以便将最终的检测结果还原到原始输入图上。
quantization:
data_type: # 指定模型的量化数据类型
'*': uint8 # 设置模型所有的参数都为uint8类型
dataset:
- ./*.jpg # 模型量化时需要提供标定图片,这是指定当前目录下所有的jpg图片为标定图片
Synap转换工具支持将模型量化为int8、uint8、int16类型,此外还支持8位和16位的混合量化, 从而保证模型量化后的精度。对于用于量化模型的标定数据集,可从训练集中抽取能表征整个数据集分布的多张图片, 不建议选用整个训练数据集作为标定数据集,因为这会大大增加模型的量化时间; 用户可针对训练数据集,充分选取不同场景下数张图片组成标定数据集即可。
设置好yaml文件后,即可执行模型量化和转换命令。相比先前单纯的模型转换,
此时converted目录下多出记录量化信息的文件 quantization_info.yaml 以及一些其他中间文件。
这里我们贴出转换前后的文件目录:
转换工作目录(这里我们只选用了一张标定图片):

生成的Converted目录内容如下:

关于yaml文件更多参数设置可参考文档: 使用模型
四、demo运行
4.1 安装adb
以ubuntu系统为例(若已安装,可跳过)。
sudo apt-get update
sudo apt-get install android-tools-adb
输入 adb version ,验证是否安装成功。如果看到类似于 Android Debug Bridge version X.X.X 的输出,
则表示 ADB 已正确安装。
4.2 连接设备
1、检测是否连接到设备
adb devices
若输出如下,则表示SL1680芯片板连接成功:

ADB连接设备
2、将量化模型和测试图片push到芯片板中
adb push your/path/model.synap /home/weston/model.synap
adb push your/path/test.jpg /home/weston/test.jpeg
3、板端运行模型
adb root
adb remount
adb shell # 之后进入到板侧终端模式
cd /home/weston # 切换到存放模型和图片的路径下
synap_cli_od -m model.synap test.jpeg # 调用synap_cli_od接口执行模型推理
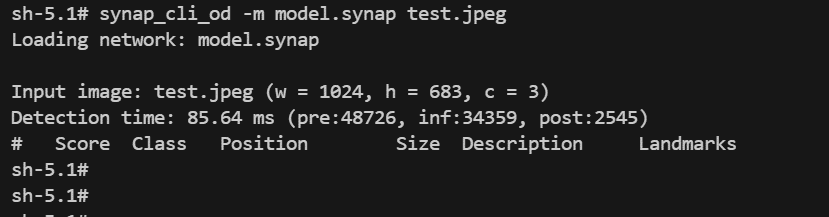
运行模型
通过板侧终端看到,虽然模型成功执行了推理,但是并没有检测到目标;说明此时得到的量化模型精度下降严重。 为此,我们需要优化量化过程。常用的两种优化方法,
一是增加量化时的标定数据集,使标定数据集更能符合训练数据集的数据分布。 这里我们仅使用了一张标定数据,因此我们可以增加标定数据集,从而实现更好的量化效果。
这里我们选择第二种优化方式,即使用混合精度去量化模型;在量化时,选择模型中一些关键节点, 将其之后的节点量化为int16位,其余节点仍然量化为8位。这样在提高模型精度的同时也尽可能保证了模型的推理时间。
关于如何选取模型的关键节点,synap工具提供了量化时计算每个节点的熵值,熵值越大, 则该节点量化后精度下降越严重,那么就可以对该节点选用16位数据类型去量化 (这里不过多展开熵值的计算方式)。
此外,对于模型而言,越靠近网络输出端,对噪声越敏感,也越容易受到干扰, 造成精度损失。因此可以对近输出端节点使用int16位去量化 (具体细节可见 使用模型 )。
结合网络结构分析,我们选取了3个节点对其使用int16位量化,见下图:

在yaml文件中,我们做出修改:
quantization:
data_type:
/model.22/Concat_3...: int16
/model.21/cv1/conv/Conv...: int16
/model.18/cv2/conv/Conv...: int16
'*': uint8
之后对模型重新进行量化和转换,并将得到的量化模型再次烧入板端测试,得到结果如下图。 可以看到有正确的检测结果。且我们对比推理时间,采用混合精度量化的模型相比纯8位量化模型, 在推理时间上仅仅增加约2.2ms (inf表示模型推理耗时,单位微秒)。
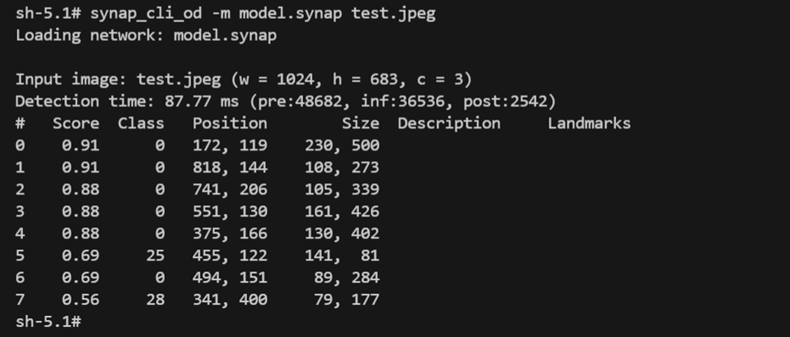
推理时间
为进一步验证检测结果,我们将检测结果显示到原图上,得到输出图如下:
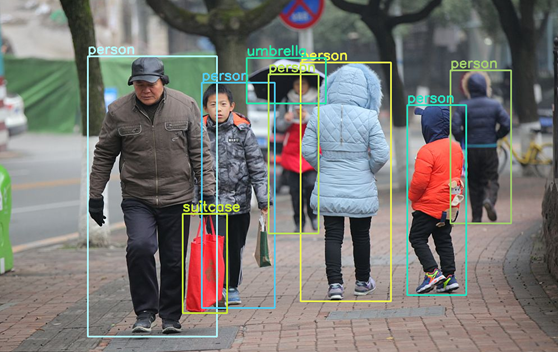
检测结果
最后,针对模型的量化优化,本文只是罗列了一种方法。 实际使用中用户可根据自身使用情况不断去调整,如选取更优的节点混合量化、增加标定数据集、对网络进行剪枝等。 更多细节可参考: 导入流程示例 。