介绍
The purpose of SyNAP is to support the execution of neural networks by taking advantage of the available hardware accelerator. The execution of a Neural Network, commonly called an inference or a prediction, consists of taking one or more inputs and applying a neural network to them to generate one or more outputs. Each input and output is represented with an n-dimensional array of data, called a Tensor. Execution is done inside the Network Processing Unit (NPU) hardware accelerator. In order to do this, the network has to be converted from its original representation (e.g. Tensorflow Lite) to the internal SyNAP representation, optimized for the target hardware.
This conversion can occur at two different moments:
at runtime, when the network is going to be executed, by using a just-in-time compiler and optimizer. We call this Online Model Conversion.
ahead of time, by applying offline conversion and optimization tools which generate a precompiled representation of the network specific for the target hardware. We call this Offline Model Conversion.
在线模型转换
Online model conversion allows to execute a model directly without any intermediate steps. This is the most flexible method as all the required conversions and optimizations are done on the fly at runtime, just before the model is executed. The price to be paid for this is that model compilation takes some time (typically a few seconds) when the model is first executed. Another important limitation is that online execution is not available in a secure media path, that is to process data in secure streams.
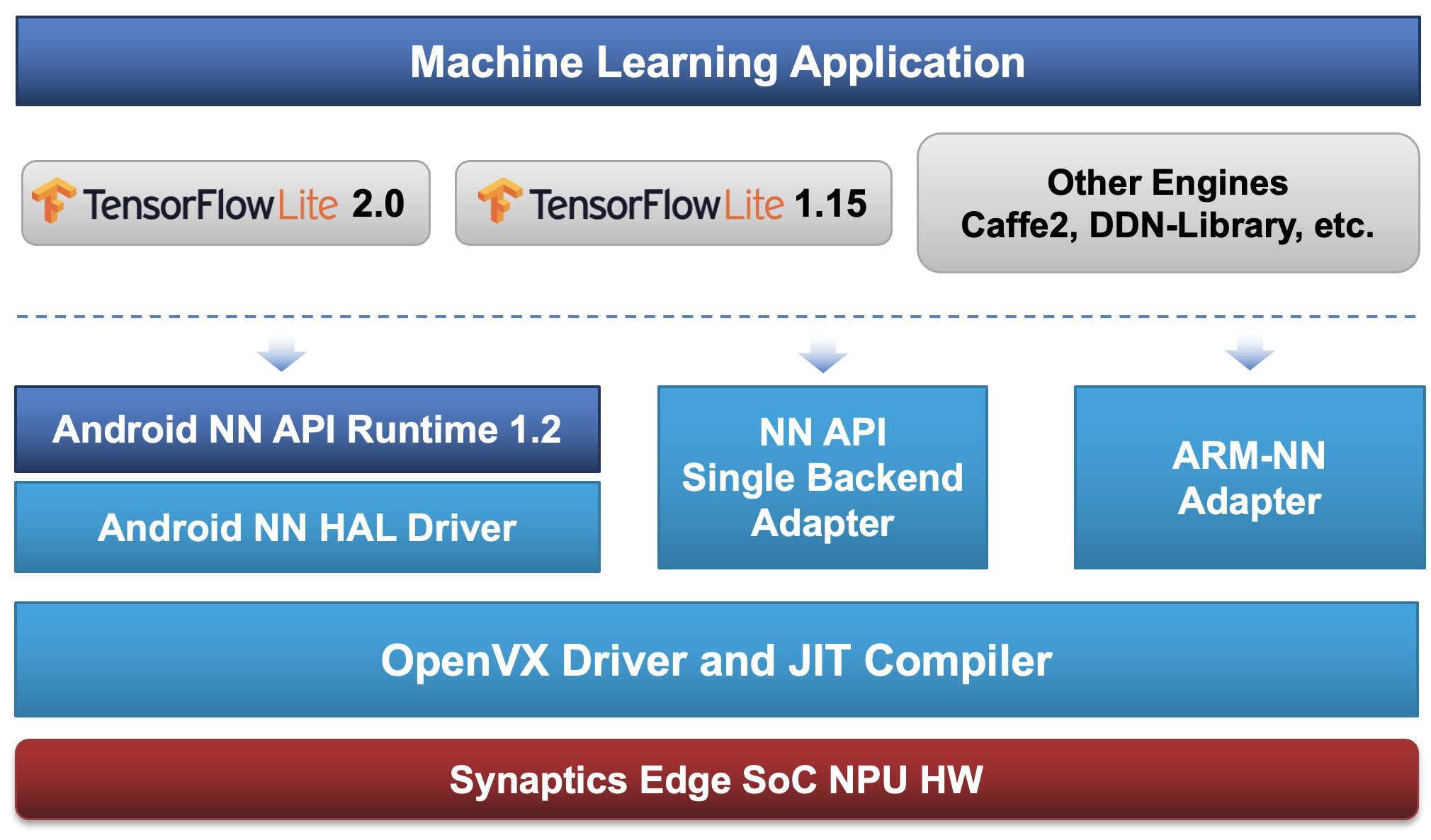
Online model conversion and execution
离线模型转换
In this mode the network has to be converted from its original representation (e.g. Tensorflow Lite) to the internal SyNAP representation, optimized for the target hardware. Doing the optimization offline allows to perform the highest level of optimizations possible without the tradeoffs of the just-in-time compiler.
In most cases the model conversion can be done with one-line command using SyNAP toolkit. SyNAP toolkit also supports more advanced operations, such as network quantization and simulation. Optionally an offline model can also be signed and encrypted to support Synaptics SyKURETM: secure inference technology.
备注
a compiled model is target-specific and will fail to execute on a different hardware
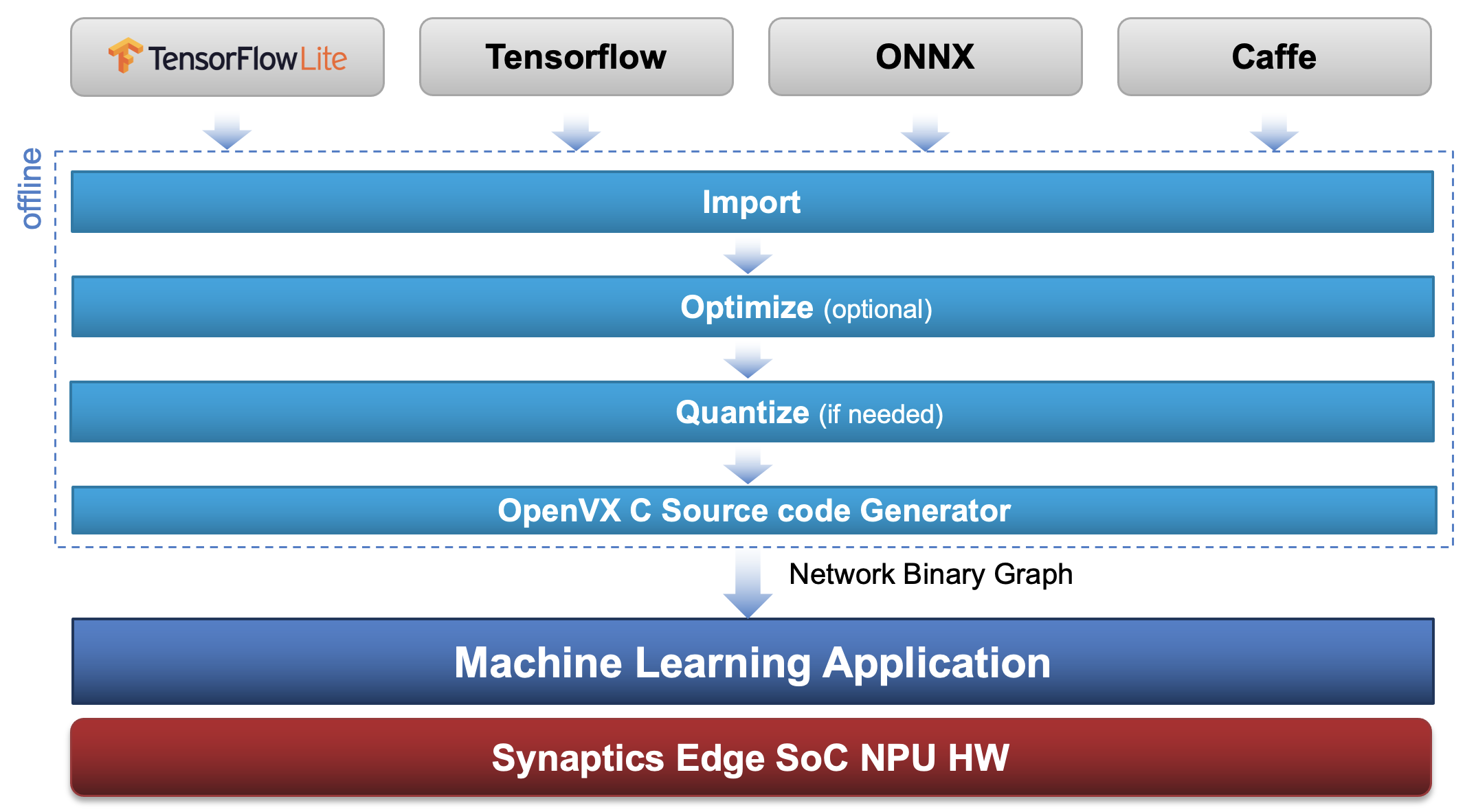
Offline model conversion and execution
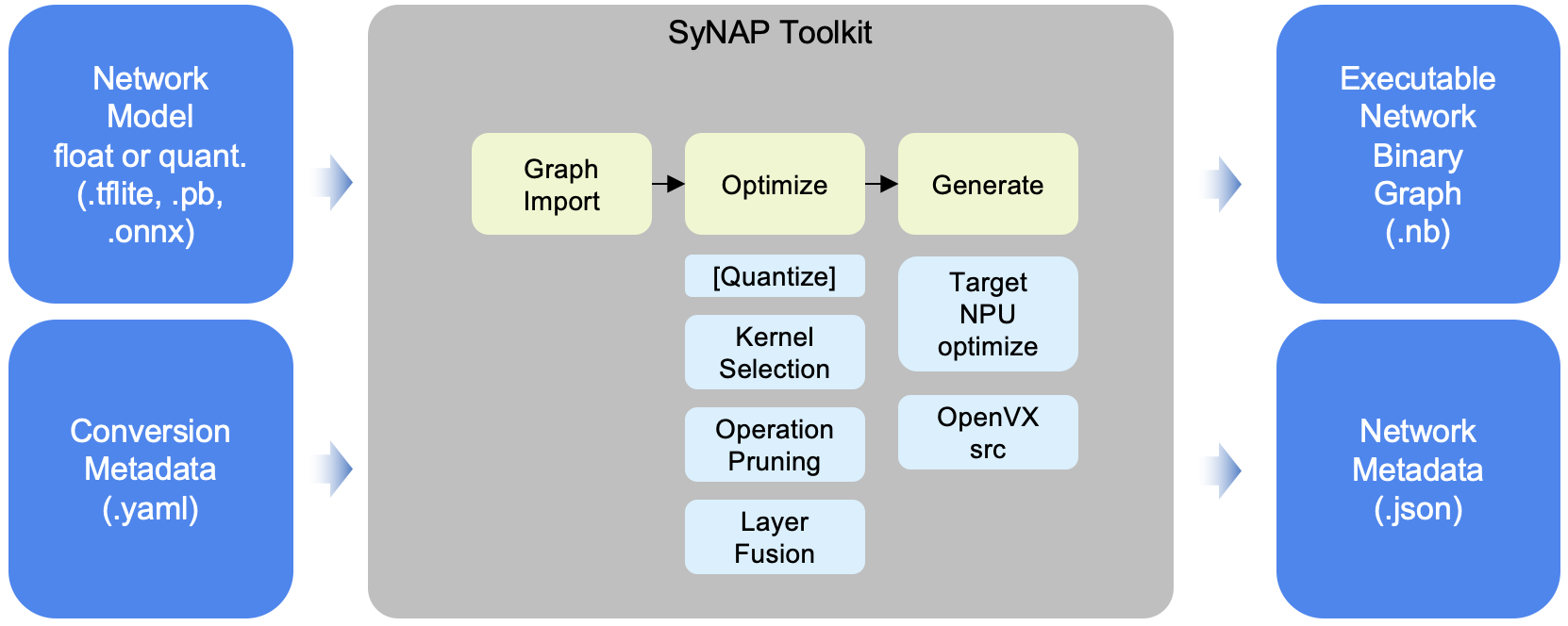
SyNAP toolkit internal view
Once compiled a model can be executed directly on the NPU HW via the SyNAP runtime.
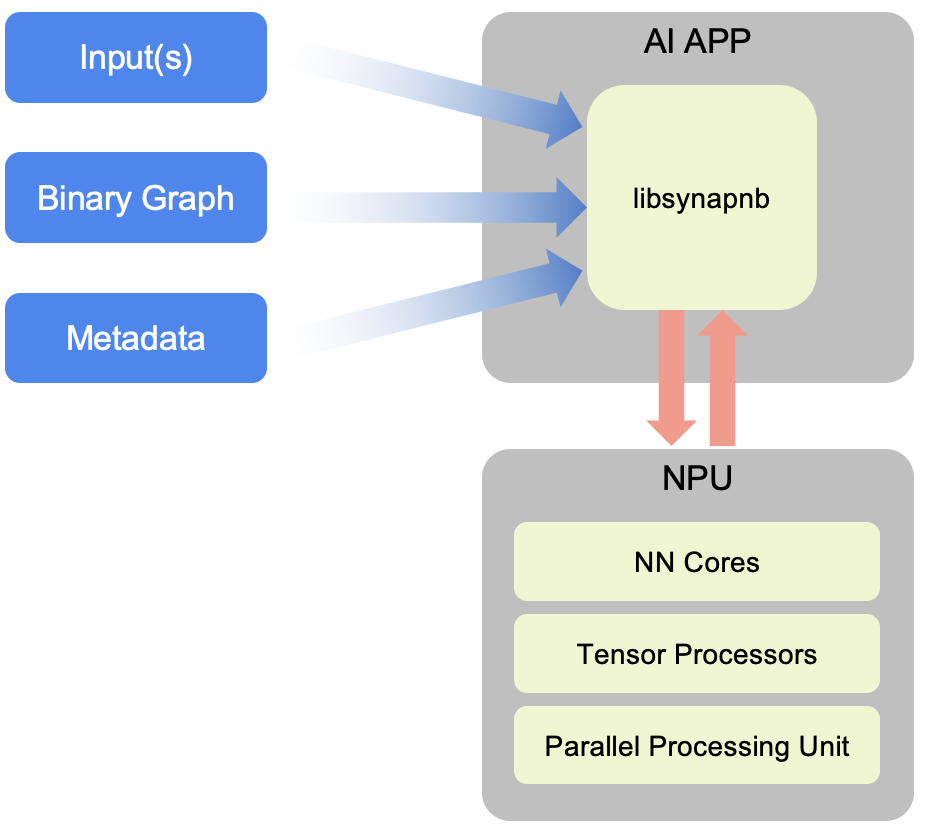
SyNAP compiled model execution